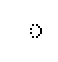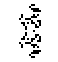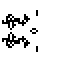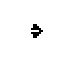Hunting wrote: ↑April 23rd, 2020, 12:56 pm
dvgrn wrote: ↑April 23rd, 2020, 11:59 am
Then again, why not make the self-documenting pattern
a little more readable? I can dig out the code I used to make that unimpressive length-13055 cyclical sample, if anyone is interested in adapting it.
Or the RLE, or the apgcode, etc. There are just too many ways to represent a constellation.
This reminded me to go back and find the script I was running a couple of years ago to try and find a self-documenting Life pattern.
The closest I've come so far is this pattern, which gets a score of 6 where the ideal score is zero:
Code: Select all
x = 117, y = 47, rule = B3/S23
5obo3bob3o2b4o5b4o3b3o2b5ob5ob5ob4o2bo3bob2o2b4o6b3o3b4obo3bo$2bo3bo3b
o2bo2bo9bo3bobo3bo3bo5bo3bo5bo3bobo3bo2bobo9bo3bobo5bo3bo$2bo3bo3bo2bo
2bo9bo3bobo3bo3bo5bo3bo5bo3bob2o2bobo2bo9bo3bobo5bo3bo$2bo3b5o2bo3b3o
6b4o2bo3bo3bo5bo3b4o2b4o2bobobo5b3o6bo3bo2b3o2b5o$2bo3bo3bo2bo6bo5bo5b
5o3bo5bo3bo5bobo3bo2b2o8bo5b5o5bobo3bo$2bo3bo3bo2bo6bo5bo5bo3bo3bo5bo
3bo5bo2bo2bo3bo8bo5bo3bo5bobo3bo$2bo3bo3bob3ob4o6bo5bo3bo3bo5bo3b5obo
3bobo3bo4b4o6bo3bob4o2bo3bo4$b3o3b3o2bo3bob5o2b3o2b3obo3bo2b4o6b2o3b2o
6b4o2b5ob5obo3bob3obo3bob5o2b4o$o3bobo3bobo3bo3bo3bo3bo2bo2bo3bobo9bo
2bobo2bo5bo3bobo5bo5bo3bo2bo2bo3bobo5bo$o5bo3bob2o2bo3bo3bo3bo2bo2b2o
2bobo12bo4bo5bo3bobo5bo5bo3bo2bo2bo3bobo5bo$o5bo3bobobobo3bo3bo3bo2bo
2bobobo2b3o8bo4bo6b4o2b4o2b4o2b5o2bo2bo3bob4o3b3o$o5bo3bobo2b2o3bo3b5o
2bo2bo2b2o5bo6bo4bo7bo3bobo5bo5bo3bo2bo2bo3bobo9bo$o3bobo3bobo3bo3bo3b
o3bo2bo2bo3bo5bo5bo4bo8bo3bobo5bo5bo3bo2bo3bobo2bo9bob2o$b3o3b3o2bo3bo
3bo3bo3bob3obo3bob4o6b4ob4o5b4o2b5ob5obo3bob3o3bo3b5ob4o3bo$110bo3$3o
7b4obo3bob3ob4o3b4o9b3o6b3o2bo5b3ob3o3b5ob4o3b4o$3bo5bo5bo3bo2bo2bo3bo
bo12bo8bo3bobo6bo2bo2bo2bo5bo3bobo$3bo5bo5bo3bo2bo2bo3bobo12bo8bo5bo6b
o2bo3bobo5bo3bobo$b2o7b3o2b5o2bo2b4o3b3o9b3o6bob3obo6bo2bo3bob4o2b4o3b
3o$3bo9bobo3bo2bo2bo9bo8bo2bo5bo3bobo6bo2bo3bobo5bobo7bo$3bo9bobo3bo2b
o2bo9bob2o5bo2bo5bo3bobo6bo2bo2bo2bo5bo2bo6bob2o$3o6b4o2bo3bob3obo5b4o
3bo6b2o7b4ob5ob3ob3o3b5obo3bob4o3bo$37bo55bo3$4o5bo6b3o3b3o2bo3bob5o2b
4o8bo2bo2b2o6b4o2bo5b3obo3bobo3bob5ob4o3b4o$3bo5bo5bo3bobo3bobo3bobo5b
o12bo2bobo2bo5bo3bobo6bo2bo3bobo2bo2bo5bo3bobo$2bo6bo5bo3bobo3bobo3bob
o5bo12bo2bobo2bo5bo3bobo6bo2b2o2bobobo3bo5bo3bobo$2bo6bo5bo3bobo3bobo
3bob4o3b3o9b4obo2bo5b4o2bo6bo2bobobob2o4b4o2b4o3b3o$bo7bo5bo3bob5obo3b
obo9bo11bobo2bo5bo3bobo6bo2bo2b2obobo3bo5bobo7bo$bo7bo5bo3bobo3bo2bobo
2bo9bob2o8bobo2bo5bo3bobo6bo2bo3bobo2bo2bo5bo2bo6bob2o$bo7b5o2b3o2bo3b
o3bo3b5ob4o3bo8bo2b2o6b4o2b5ob3obo3bobo3bob5obo3bob4o3bo$45bo66bo3$4o
5b4o3b3o3b3o2b5o2b4o6b3o2bo3bob3o7b3o3b2o6b4o2bo6b3o3b3o2bo3bo2b4o$3bo
5bo3bobo3bobo3bo3bo3bo9bo3bobo3bobo2bo9bobo2bo5bo3bobo5bo3bobo3bobo2bo
2bo$2bo6bo3bobo3bobo3bo3bo3bo9bo3bob2o2bobo3bo8bobo2bo5bo3bobo5bo3bobo
5bobo3bo$2bo6b4o2bo3bobo3bo3bo4b3o6bo3bobobobobo3bo6b2o3b3o5b4o2bo5bo
3bobo5b2o5b3o$bo7bo3bobo3bob5o3bo7bo5b5obo2b2obo3bo8bo4bo5bo3bobo5bo3b
obo5bobo7bo$bo7bo3bobo3bobo3bo3bo7bo5bo3bobo3bobo2bo9bo4bo5bo3bobo5bo
3bobo3bobo2bo6bob2o$bo7b4o3b3o2bo3bo3bo3b4o6bo3bobo3bob3o7b3o2b3o6b4o
2b5o2b3o3b3o2bo3bob4o2b2o!
The pattern really does produce seven loaves, 40 blinkers, and 22 beehives, but its self-prediction is one off on number of ponds, ships, boats, tubs, gliders, and blocks. The score is the sum of the squares of the difference between actual object counts and predicted object counts, with "unknown cell" being a catchall kind of defined object whenever rare stuff pops up.
The average number of tubs and ponds in each final constellation for a sentence of this size (with seven objects listed) is a little bit over 1. The idea here was to try a search run with a shorter sentence, which produces less ash on average. I'll probably go back to including "1 tub, 1 pond" in the next round of searches, since that prediction is more likely to be correct... even though it also increases the average count of all the other object types slightly, and thus makes it a little less likely that any given prediction will actually come true.
Operator's Manual
I won't spend too much time documenting the script, since the right thing to do next is probably to rewrite it using lifelib to get it running an order of magnitude or two faster. But if anyone wants to try running it, the key points are
1) replace text.py in your copy of Golly, in Scripts/Python/glife/, with the version in the archive.
2) Maybe think of some unique wording for the beginning or end of the sentence, so you're guaranteed not to be running a search I've already tried. Change the
standardtext variable appropriately.
3) First temporarily set the
countfirstN variable to 1000 or 10000 or something, to find out what the average counts are for each still life being named.
4) Once you have those averages (they're copied to the clipboard when the cycle count hits
countfirstN) ... set
countfirstN back to 0, set up appropriate search ranges for each variable in the
minimaltarget dictionary, and re-run the script.
The script reports the count of population matches in the status bar, the average distance between population matches, and the best score seen so far for patterns with a population match. (If the final ash's population doesn't match the target population, the script doesn't bother doing a slow census of the final ash, since it can't possibly be right anyway.)
The script runs through all permutations of the objects listed in the
minimaltarget dictionary, and all the sizes of spaces between words implied by the setting of the
maxspace variable, and all the object counts between the minimum and maximum values given in the
minimaltarget dictionary. The script can go through several million candidates a day, but the number of permutations can quickly get up into the millions, so set ranges accordingly. If you want to stop a search before all permutations have been tested, hit the "k" key.
These Are A Few Of The Changeable Things
Other things that could be permuted include
- The text wrap width, currently hard-coded to 144 in the addnewlines() call. Text that's roughly as tall as it is wide seems to produce the least ash. However, it's possible that text with no wrap might have much lower standard deviations on its object counts, in which case it might be possible to target the average count more precisely and get a correct self-documenting sentence sooner.
-- It doesn't seem worth trying every possible wrap width, though, since some wrap-width changes don't actually result in a different pattern.
- Distance between lines. Currently this is hard-coded in the "width" of a newline character in text.py, so it would take some more serious fiddling around with the script to make this adjustable.
- Justification. Text is currently left-justified, but maybe it would look better centered.
- Presence or absence of a comma before the final "and".
- Custom adjustment of spaces between individual words. Not sure I like this option, though, because the pattern then can't be regenerated just by knowing the words in its text. A self-documenting sentence like that wouldn't necessarily be invalid, but it seems like a short step to just adding a bunch of gliders and still lifes to the initial pattern, to make the count come out exactly right -- and that does seem like cheating.